Introduction

Today, I am excited to present Validate Copilot, an AI-powered service designed to streamline and enhance the implementation of test scenarios for vehicle feature validation. This service is an integral part of the SODA.Validate solution and provides engineers with the following capabilities:
-
Generation of Implementations: Enables the creation of test suites as well as individual test cases tailored to the specified test environment.
-
Code Suggestion: Offers a list of suggested code snippets based on natural language queries, which can include inline comments within a test case implementation.
-
Code Summarization: Provides appropriate code comments in natural language that summarize given code snippets.
-
Code Placeholder Prediction: Receives code snippets before and after a gap, then responds with a list of suitable code predictions to fill the gap.
However, before diving into the features and functionality of Validate Copilot, it is essential to provide a brief overview of the SODA.Validate solution. Understanding the context of SODA.Validate will give you a clearer picture of how Validate Copilot operates within this comprehensive validation framework.
SODA.Validate Environment
In today's world, cars are becoming smarter and more complex. This makes developing and testing vehicle embedded software a significant challenge for engineers. Imagine a solution that simplifies the entire process from initial tested requirements to final certification. That's exactly what SODA.Validate is – your fast track to creating a certified vehicle.
This comprehensive platform consisted of three key components: Validate Studio, Software-Defined Rig (SDR), and Systems under Test.
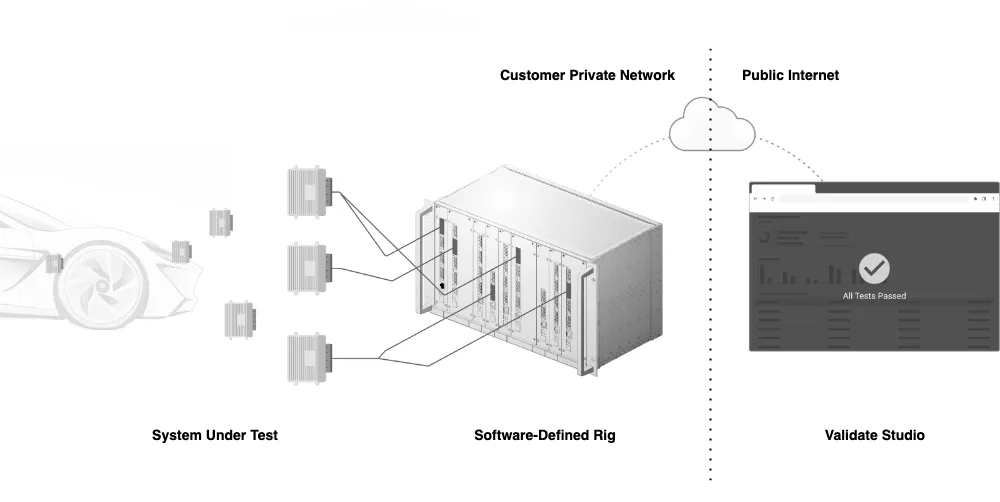
Validate Studio serves as the Test Design and Test Management System. Offered as a SaaS solution, it provides a web-based interface that simplifies and automates the process of test creation and execution. This cloud-based approach ensures that your tests are always accessible, allowing for efficient management and execution from anywhere in the world.
The Software-Defined Rig is a modular hardware-software complex designed to integrate with electric and electronic systems under test. It supports the execution of various simulation models, providing a powerful environment for MIL, SIL and HIL testing. The Rig includes modules such as Universal Input/Output, Interface Multiplexer, and Electronic Load, providing a flexible and comprehensive testing environment.
The primary user workflow can be described as follows:
-
Setting Up the Test Environment in Validate Studio: The user configures the test environment by creating the hardware topology, which includes the placement of ECUs, network configuration, wiring between ECUs and SDR, and the definition of simulation models.
-
Deploying the Configuration to the SDR: This configuration is deployed to the SDR. If the deployment is successful, the Rig is ready for operation.
-
Writing Test Scenarios: The user writes test scenarios, which will be detailed in the next section. These scenarios are crafted to align with the specific configured test environment.
-
Executing Test Scenarios on the SDR: The scenarios are sent to the SDR for execution. The Rig, in real-time, sends back a report to Validate Studio on the execution status of the scenarios.
The integration of Validate Studio with the Software-Defined Rig using DDS (Data Distribution Service) via the internet allows them to be placed in different parts of the world. This setup enables users to connect vehicle ECUs to the Software-Defined Rig and run tests through the Validate Studio web application, regardless of geographical limitations.
In SODA.Validate, we utilize the Robot Framework, a highly versatile open-source automation framework, to implement test scenarios. This choice is driven by the convenient syntax of Robot Framework, extensive library support, and easy ways to extend the syntax. To enhance the capabilities of Robot Framework and tailor it to the specific needs of our test environment, we have developed a custom library known as the SODA Keywords Library. This library extends the basic set of keywords provided by Robot Framework, enabling more specialized interactions with our test environment configured on the Software-Defined Rig.
These custom keywords allow interaction with CAN messages and signals, manipulation of ECU pins, management of running simulation models, and more. Here's a simple example of how a test case might look:
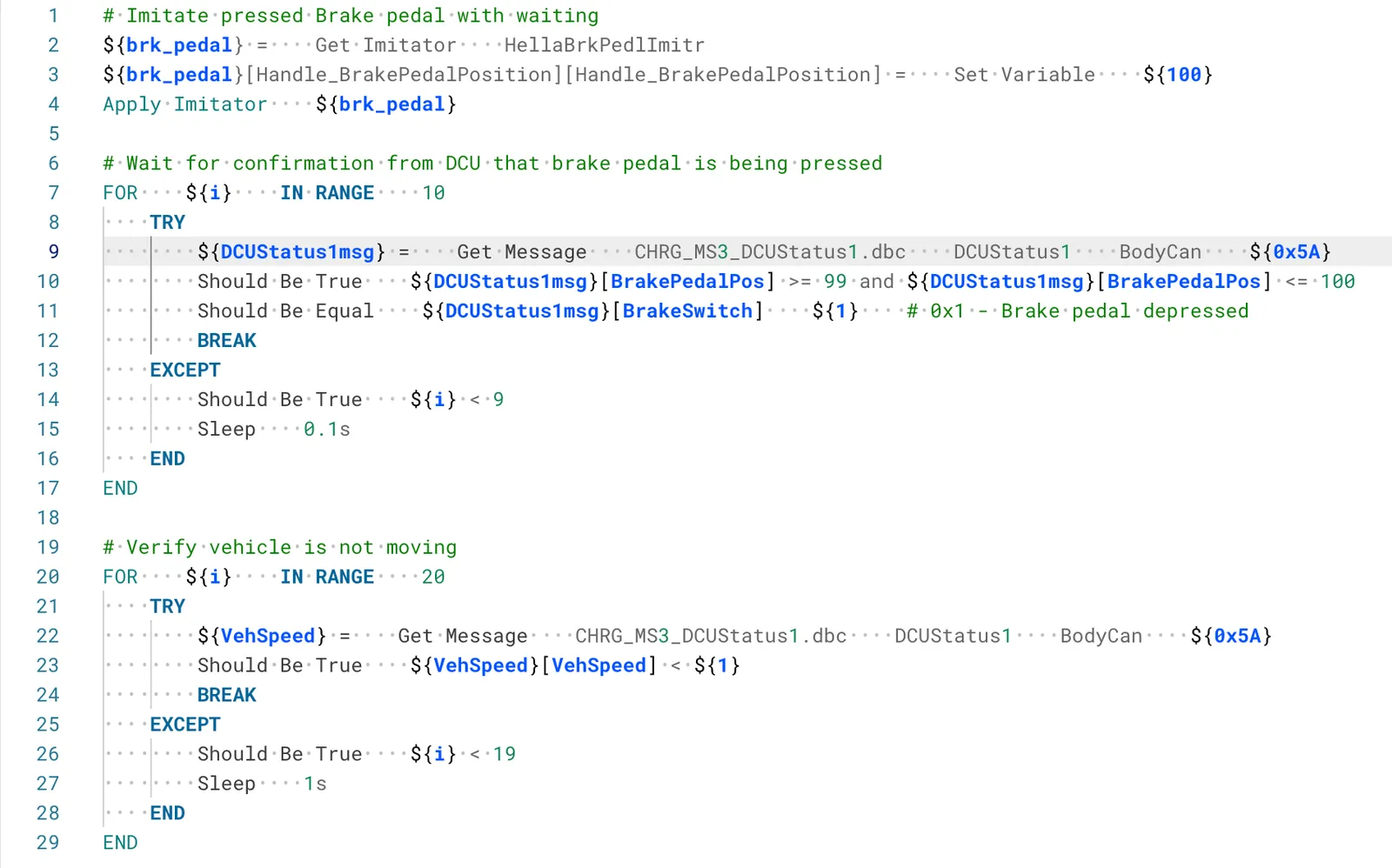
In this example, we simulated pressing the brake pedal using the corresponding imitator, then verified this action by checking the signal values in the message sent by the DCU, and finally confirmed the vehicle's stop by examining the speed value in the message from the DCU.
As you can see, by combining Robot Framework's user-friendly syntax with the specialized capabilities of the SODA Keywords Library, SODA.Validate enables engineers to create sophisticated test scenarios that closely mimic real-world automotive conditions.
Why We Developed Validate Copilot
The emergence of a service like Validate Copilot was primarily driven by the requests of our QA engineers, who use SODA.Validate daily in their work. To address this need effectively without reinventing the wheel, we closely examined existing solutions on the market.
Currently, all generative programming AI tools lack the ability to comprehensively analyze your entire codebase, significantly limiting their overview and often forcing them to guess how your codebase fits together for the task at hand. For instance, GitHub Copilot currently only reviews the current file and other files you may have open in your editor.
However, at SODA, we use our own SODA Validate Keywords library, which extends the existing Robot Framework language. It is clear that none of the available models are familiar with our unique keywords library. This is precisely why we decided to develop a service that could not only generate test scenarios but do so with an intimate understanding of our SODA.Validate environment.
Choosing the Right Approach
There are only two ways for companies to feed external data into existing Large Language Models (LLM): fine-tuning and retrieval augmented generation (RAG).
Fine-tuning
A few words about fine-tuning and why it's not applicable in our situation. Yes, fine tuning involves providing a list of example prompt/completion pairs to the model to adjust its weights to have a bias towards tokens that appear frequently in the provided examples. As long as the examples include information from your external dataset, the fine-tuned model will generate completions that use that information. But there few unresolving problems for us:
-
Frequent Model Tuning: When the source of truth changes, models must be retrained to accommodate the new information. In our case, the language we use to write test scenarios is still in its early stages and is bound to evolve in the future. Additionally, as the amount of test scenarios grows, we intend to use these scenarios as a learning dataset. Given these factors, we will likely need to fine-tune our model repeatedly.
-
Even More Frequent Tuning: As you may notice, each keyword usage contains parameter values specific to a particular testing environment. Moreover, the configuration of the testing environment can change during the test design process. Thus, fine-tuning a model on these environment settings is not feasible for obvious reasons. Yes, it's possible to train the model on keywords where parameters do not have specific values and then implement the substitution of parameter values using built-in functions capable of parsing the testing environment configuration to find consistent parameter values. However, often a parameter's value could be, for instance, a human-readable name of a signal or message, which could be utilized in generating a copilot's answer to a user prompt. Therefore, we discarded the idea of using functions.
-
Multi-Tenant Data Isolation: SODA.Validate is primarily a SaaS solution that supports a multi-tenant mode of operation with strict data isolation for each tenant. Implementing model fine-tuning for Validate Copilot would necessitate creating separate instances of the model for every tenant. Additionally, each instance would require ongoing fine-tuning with the data generated during the tenant's use of SODA.Validate. This approach presents significant challenges in terms of implementation complexity and scalability, making it impractical for our needs.
-
Response Origin Uncertainty: Fine tuning does not provide the ability to prove the provenance of responses. It’s difficult to measure the impact of fine tuning because responses are non-deterministic. Simply put, we couldn't determine whether the answer was generated based on our SODA Validate Keywords library or if it was from the knowledge of a pre-trained model from a public repository on GitHub containing another Robot Framework library.
Therefore, we decided against fine-tuning our own generative model for Validate Copilot and chose a different approach.
Retrieval Argument Generation
Considering all the drawbacks associated with fine-tuning, we decided to use the RAG (Retrieval-Augmented Generation) approach. Let me briefly explain what this entails, so we can use consistent terminology throughout the rest of the article.
The RAG technique involves taking external data, generating embeddings from it, and uploading it to a vector database. Whenever a user has a query, you perform a semantic search on your vector database to find the data that’s most relevant to the query. Then, you feed the results of the query into the LLM’s context window, giving it access to information not present in its training data which it can summarise and use to respond to the query.
LLM store “representations” of knowledge in their parameters. By passing relevant contexts and questions into the model, we hope that the model will use the context alongside its “stored knowledge” to answer more abstract questions.
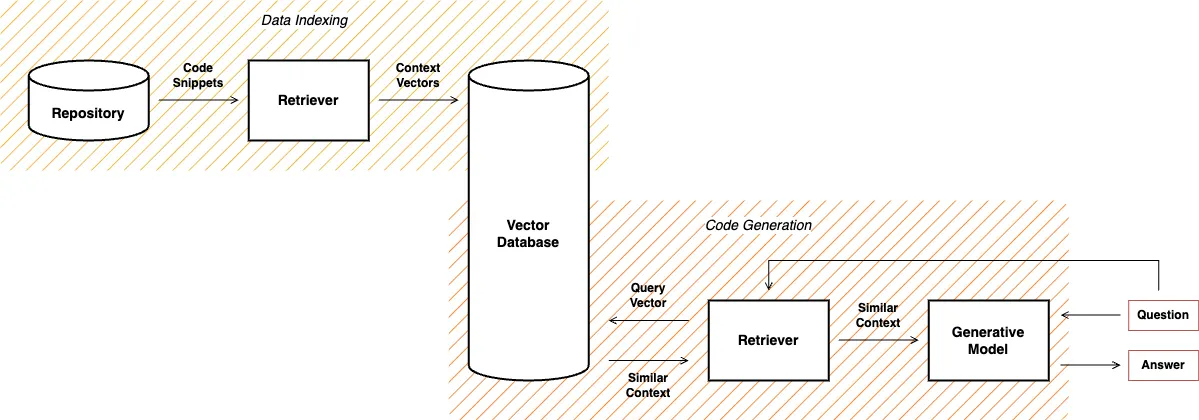
So, on the first phase we need to prepare our code base to be able to semantically looking up over it - Data Indexing. Semantic code search is the task of retrieving relevant code given a natural language query. It requires bridging the gap between the language used in code (often abbreviated and highly technical) and natural language more suitable to describe vague concepts and ideas.
In this architecture, the key concept is the Retriever: a pre-trained model that encodes questions and contexts into the same vector space. These context vectors are then stored in a vector database. In our case, the context vectors will consist of code snippets of test scenarios related to the same test environment. For this, we use a public high-performance model trained on a dataset specific to programming languages.
Vector Database is used to store context vectors that numerically represent the meaning of code snippets from our private repository. Such precompiled index in the database allows us quickly looking up context relevant to a received query.
When the database is fulfilled we can implement the second part of our pipeline - Code Generation. We user the same retriever model to encode questions to be compared to the context vectors in the vector database to retrieve the most relevant contexts.
The retriever then needs to be wired together with the Generative Model. A straightforward way to do this is to put retrieved snippets directly into the prompt sent to the code generation model. There is a wide range of applications, which leverage LLMs to understand language, imagery, and code, can answer questions, summarise code, and provide predicted code snippets. Also, most of these applications has a public API which allows us to provide previously founded context as a part of the prompt together with the original question. It gives us an ability to use such applications as the code generation model in our pipeline.
Data Specific for RAG Approach
Let's revisit the drawbacks highlighted with the use of fine-tuning and how they are mitigated by adopting the RAG approach. As I mentioned before, we need to fine-tune our generative model each time we make changes to the test environment configuration, as this directly affects the parameter values of the invoked keywords.
For example, to send a CAN message to a specific network:
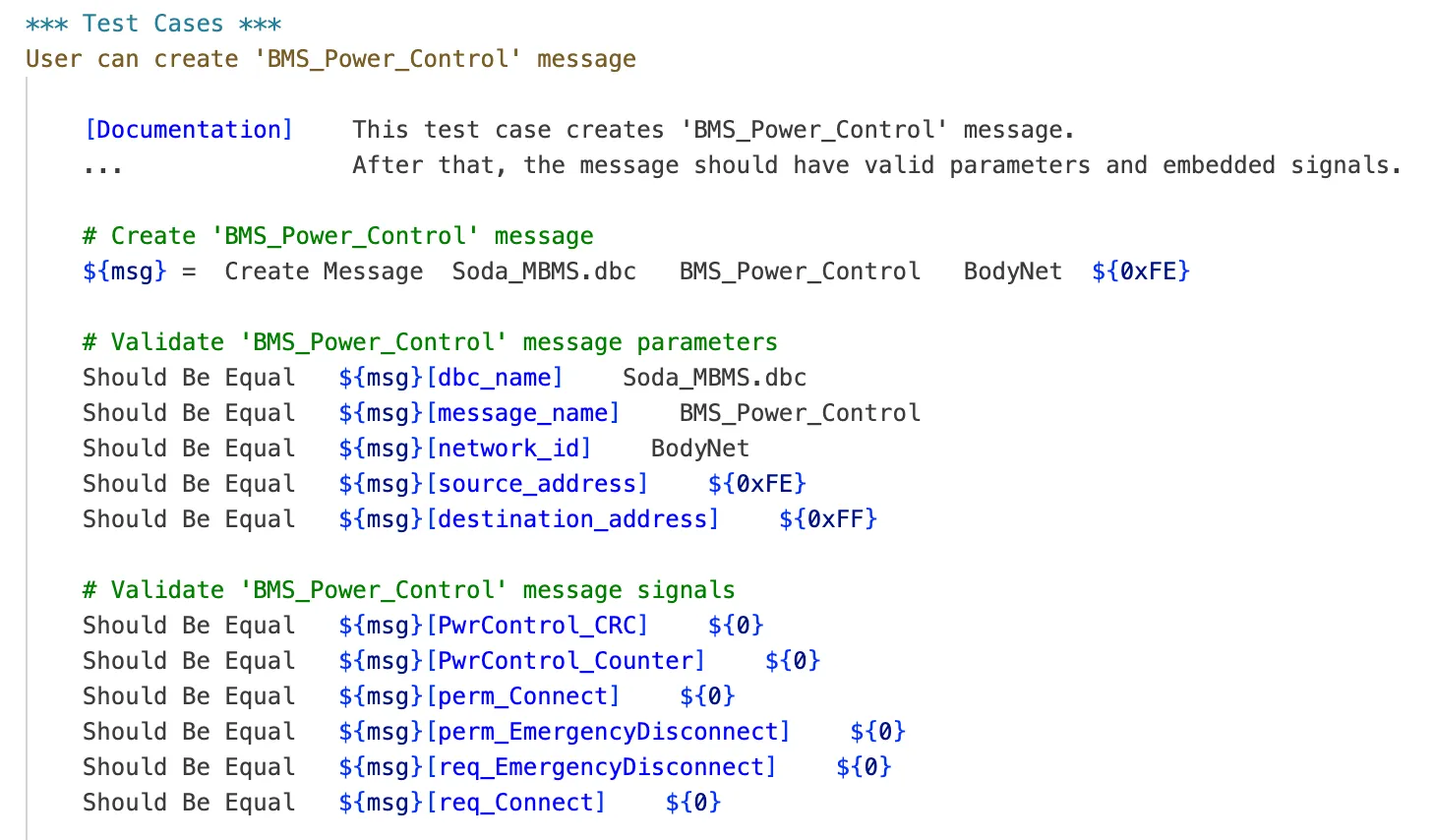
As you may notice, the keyword usage contains parameter values specific to a particular testing environment. With RAG approach the Retriever provides only those code snippets of test scenarios that make sense within the testing environment where the test will be conducted. The generative part, knowing only the basic syntax of the Robot Framework language but receiving context examples from the Retriever and the instruction to use only these code snippets, can generate a test scenario which is compatible with the given testing environment.
Another concern was about multi-tenant data isolation. Just to remind you, the data generated by a tenant during operation is indexed and becomes part of the search index for semantic search. This data includes test environment configurations and test scenarios. Let's explore how this is organized in terms of data isolation:
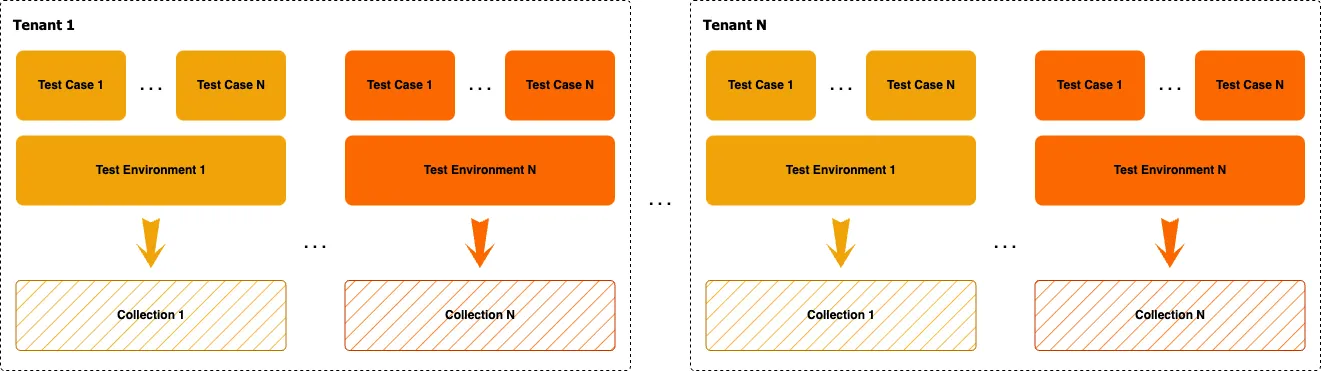
It's worth noting that SODA Validate is a multi-tenant SaaS solution in which each tenant can configure an unlimited number of testing environments. Additionally, for each environment, a tenant can write an unlimited number of test scenarios. Each test environment configuration and its associated test scenarios are transformed into a collection of embeddings, which the Retriever uses to provide a coherent context for the Generative Model. These collections are continually updated as new test scenarios are created.
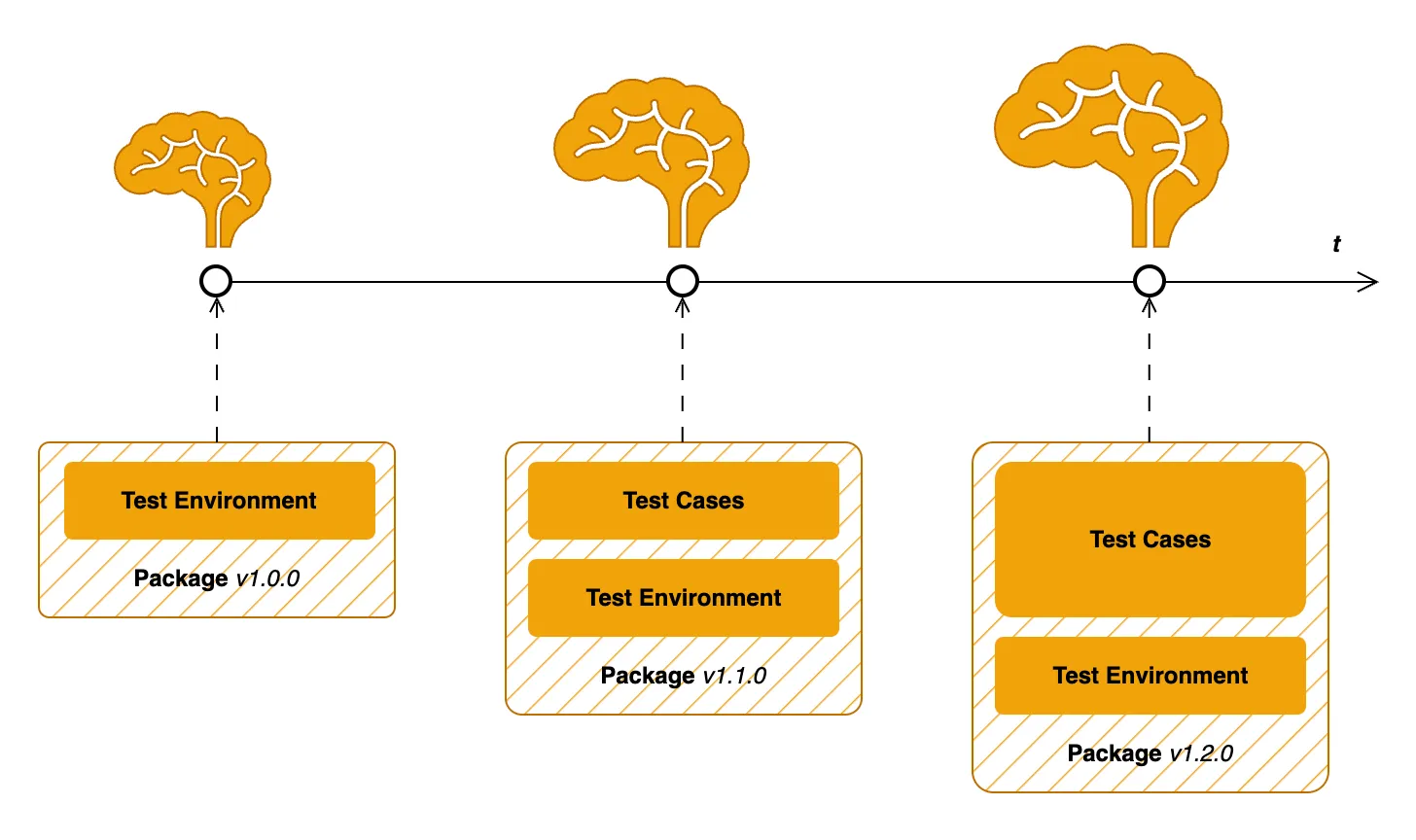
As test scenarios are written for a specific testing environment, it can be said that Copilot becomes smarter. This is because the search index now includes not only synthetically generated test examples based on the published specifications of the test environment, but also user-written test scenarios that have been validated. Thus, Validate Copilot begins to recognize the patterns and specifics of test scenarios used by QA engineers.
Technical Highlights of the Solution
In this section, I just want to highlight the features of our solution without delving into technical details, as this will be covered in the second article of this series.
What We Use as Data Source
It is quite evident that test scenarios written by users could be used as a data source for populating the search index. This index is later used to retrieve examples of test keyword usage for the Generative Model. How could we effectively "explain" our test environment configurations to the Generative Model? These configurations encompass a wealth of critical information: the hardware topology, such as the placement of ECUs, network configuration, wiring between ECUs and SDR, and the definition of simulation models. All this information is contained in descriptors (.xml files conforming to the data format and model used in SODA to describe the domain), as well as .ldf and .dbc files that describe the message format.
We decided to convert all this data into tests, generating .robot files that contain synthetic test scenarios. These tests essentially verify the correct installation of the configuration on the SDR, in other words, they "probe" the configured test environment.
A set of transformers was created to convert data from various formats into a common domain model, and then generate test scenarios from this model. Thus, we obtain successfully executed tests on the current test environment, which are subsequently fed into the generative model's context as examples. In essence, we expose the test environment configurations for the Generative Model through these test examples. This approach allows our model to gain a deep understanding of the underlying hardware and network configurations, enabling it to generate more accurate and context-aware responses.
How We Split Code Files
In our innovative approach, .robot files are segmented into logically complete parts, with each part comprising a code comment and its corresponding code snippet. Exceptions are made for short test cases with a [Documentation] section, which are indexed as a whole to preserve the logical sequence of keyword invocations.
We use TreeSitter to create concrete syntax tree (CST) for .robot files, mapping out the structure according to the language's grammar. For that reason we created a new grammar file for Robot Framework language that defines the syntax of it. This file specifies the rules and structure of the language. And based on this grammar file we created the parser for .robot files.
Using TreeSitter, we can accurately identify and link comments with their corresponding code snippets, ensuring that the context around the extracted fragment and its structural integrity are preserved. For example, this approach easily handles situations where users create their own keywords for tests. In such cases, the extracted fragment includes not only the keyword invocation but also its implementation, thereby preserving the structural integrity of the code. Or we can easily link variable declarations at different levels of a test scenario with the use of these variables in keyword invocations within the extracted fragments. This ensures that the context and dependencies are maintained throughout the code analysis process.
How We Deal with Semantic Search Results
When we receive results from the Retriever in our Generative Model, our goal is to present as diverse a set of results as possible. However, we are constrained by the context size and cannot include all results directly. To address this, we cluster the results and select a proportional number of results from each cluster based on their relevance to the initial query.
First, we reduce the dimensionality of all retrieved results using Principal Component Analysis (PCA) while retaining 95% of the variance. This step ensures that the essential features of the data are preserved while making the clustering process more efficient.
Next, we determine the optimal number of clusters using the Silhouette method, which evaluates how similar an object is to its own cluster compared to other clusters. This method helps us identify a well-defined structure within the data, ensuring that each cluster is meaningful and distinct.
After clustering, we distribute all results into clusters and rank them by their distance from the cluster center. This ranking allows us to prioritize the most representative results within each cluster. We then select the top results from each cluster, with the number of results chosen proportionate to the cluster's relevance to the initial search query. This approach ensures that the Generative Model receives a diverse yet relevant set of context results.
We experimented with various clustering methods and found that this approach yielded the best results for our data. By balancing diversity and relevance, we enhance the model's ability to generate accurate and comprehensive responses.
What We Use as Generative Model
In our implementation, we use the OpenAI Assistant API as our Generative Model, feeding it examples of our keyword usage obtained through semantic search. Initially, we utilized the standard OpenAI API without the assistance feature. However, we realized the potential of our comprehensive keyword library documentation for more precise code generation. Recognizing this, we developed an Assistant based on our documentation, engaging with the Generative Model using separate threads per user. This approach allowed the model to reference specific documentation and examples, significantly improving the accuracy of code generation.
One major issue we faced was the Generative Model's difficulty in generating correct parameter sequences due to our use of positional parameters instead of named parameters. Without knowledge of the parameter positions, the model struggled to produce accurate results. By integrating our documentation into the Assistant, we provided the necessary context, enabling the model to understand the positional parameters and generate correct sequences. This adjustment greatly enhanced the reliability of Validate Copilot, reducing errors in keyword invocation.
In summary, by transitioning to the OpenAI Assistant API and incorporating our detailed documentation, we have significantly improved the functionality and accuracy of Validate Copilot.
Conclusion
Validate Copilot is a prime example of how the effective integration of AI can accelerate the development of automotive functionalities. This integration has led to a more than twofold reduction in the time required to write tests, thereby streamlining the validation process for automotive embedded software.
The success of Validate Copilot highlights the potential of AI-driven tools in transforming the development landscape. The key to this transformation lies in the seamless integration of domain-specific knowledge and AI capabilities. By providing contextually accurate examples and detailed documentation, AI tools can effectively assist developers, reducing errors and enhancing productivity.